SYSC 5800: Network
Computing
Sample
Solution to Final Exam, Winter 2007
Question 1. Network Addresses
(10 marks)
1. In the Internet, how many different ways exist to address a specific endhost. Assume you are dealing with a PC-type device, with only one Network Interface Card. How are these addresses related to each other (i.e., how can an Address of type X be translated into an Address of type Y)?
Answer (5 marks):
l
Network Interface
–
Hardware/MAC address, often 48-bit IEEE
address (but not always: Bluetooth has 3 bit address dynamically assigned,
dedicated links do not need hardware addresses)
l
Hosts (well, technically interface
as well)
–
IP address (i.e. 134.117.63.134)
–
DNS name/symbolic name (i.e.,
kunz-pc.sce.carleton.ca)
The address translation is done by Internet Protocols: DNS translates from DNS names to IP addresses (and vice versa, which is called Reverse DNS lookup), ARP translates from IP address to MAC address (and vice versa, called RARP).
2. Which one(s), if any, of these addresses are just opaque, unique identifiers? Which ones have a structure? In the latter case, explain the structure and its purpose.
Answer (5 marks):
–
IP addresses are 32-bit numeric
identifiers containing network and host identifiers. Simplifies routing tables
(far away routers only need an entry per network, not per host)
–
DNS/symbolic names have a hierarchical
structure, based on well-known “top-level” domains. Simplifies resolving
(looking up) IP addresses for a given name, by navigating the DNS hierarchy as
indicated by the name.
–
IEEE MAC addresses: 24 bits identify
manufacturer, 24 bits supposedly running number uniquely identifying each NIC
built by manufacturer. Simplifies assigning unique IDs to each NIC (Network
Interface Card): manufacturers manage their own address space
Question 2. Socket Programming (10 marks)
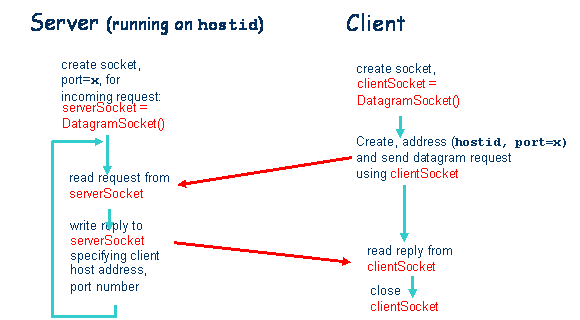
1. Describe in a diagram the interactions between a client and server using UDP sockets. The diagram should start with client and server processes starting up and end with the client process terminating.
Answer (5 marks):
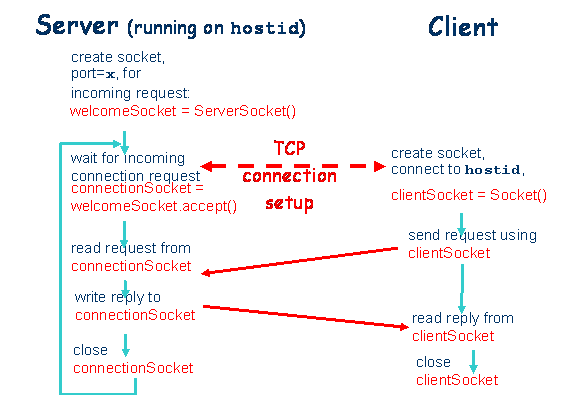
2. Describe similarly in a diagram the interactions between a client and a server using TCP sockets.
Answer (5 marks):
Question 3. RPC (10 marks)
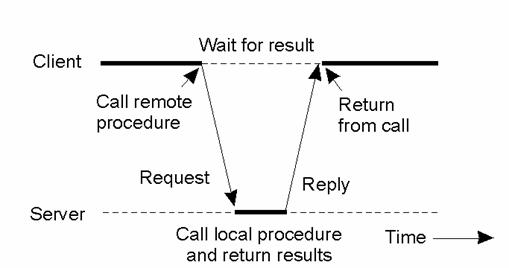
1. Describe the basic communication pattern using RPC.
Answer (2 marks):
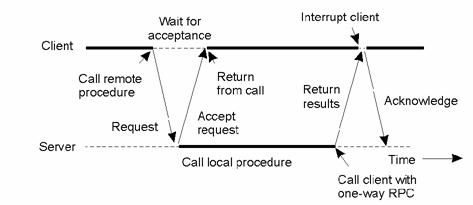
2. Discuss the shortcomings of the communication pattern and suggest an alternative communication pattern that solves that problem.
Answer (3 marks):
Blocking/Synchronous RPC does not
allow for parallelism: client is blocked while server executes, server is
blocked while client executes. To increase parallelism, support asynchronous
RPC: client invocation does not block client, return results (if there are any)
by a later message exchange.
3. Describe the basic steps when executing an RPC, based on the Sun-RPC package described in class.
Answer (5 marks):
l
Client procedure calls client stub
in normal way
l
Client stub builds message, calls
local OS
l
Client's OS sends message to
remote OS
l
Remote OS gives message to server
stub
l
Server stub unpacks parameters,
calls server
l
Server does work, returns result
to the stub
l
Server stub packs it in message,
calls local OS
l
Server's OS sends message to
client's OS
l
Client's OS gives message to client
stub
l
Stub unpacks result, returns to
client
Question
4. Tuple
Space (10 marks)
1.
Describe the basic tuple space idea: what sort of communication paradigm does
it implement, what are the communication primitives?
Answer (4 marks):
l
Completely decouples communication
entities referentially and temporally
l
Tuple-space:
persistent shared storage, processes can add tuples,
search matching tuples, and remove tuples
–
Write, read, take
l
Tuples
do not have a priori agreed-upon structure
l
Tuple
matching is called associative addressing (retrieve tuple
based on matched content)
2. In JavaSpaces, a TupleSpace
can be implemented in a number of different ways. Describe at least three
different implementations that involve storing the tuple
space across multiple machines and describe the pros and cons of each design.
Answer (3 marks):
· Fully replicated tuple space: Tuples are broadcast on WRITE, READs are local, but the removing of an instance when calling TAKE must be broadcast
· Fully distributed tuple space: A WRITE is done locally. A READ or TAKE requires the template tuple to be broadcast in order to find a tuple instance
· Partially replicated tuple space: requires partial broadcast of all operations, similar to quorum system.
3. Would a centralized implementation (i.e., the whole tuple space being managed by a centralized server) be a better solution? Explain your answer.
Answer (3 marks):
From a network perspective (number of messages), broadcasts can be as efficient as unicast messages if underlying network architecture supports broadcast over a shared medium (Ethernet, IEEE 802.11 WLAN, etc.). If underlying network only supports unicast/point-to-point messages, centralized architecture requires less communication.
Load balance/fault tolerance: distributed architectures allow certain degrees of parallelism (multiple write or read operations can take place in parallel). Also no obvious single point of failure, though distributed implementation has to take care to never wait for acknowledgements from potentially failed nodes. And in the partially replicated arrangement, it will become harder to achieve/maintain quorum as nodes/tuple space components fail.
Question
5. WWW Programming (10
marks)
Briefly describe at least three different ways of generating dynamic WWW content at the server and list advantages and disadvantages of each approach.
Answer (10 marks):
l CGI Scripts:
–
Advantages
l
Expands static WWW pages
l
Wide range of programming
languages supported
l
“easy” to use
–
Disadvantages
l
High overhead (new process per
request)
l
Low level (explicitly generate
HTML code)
l No support for state across requests (sessions, etc.)
l Servlets:
–
Characteristics: A light-weight task that
can be executed as a thread, a servlet can remain in
memory (a CGI script terminates when it finished)
–
Advantages: A servlet
can service multiple client requests, can handle multiple clients without
reloading/reinitialization
–
Disadvantages: low-level construction
of HTML documents
l
fragments (strings) written to
output stream
l
no static well-formedness/validity
guarantees
l
Low-level session management (control-flow
is often unclear, no enforcement of relation between showing a page and
receiving form input, primitive session state management)
l JSP (Java Server Pages):
–
Enables you to embed Java code within an
HTML document
–
When an HTTP request is received, the
compilation engine converts the JSP document into a Java Servlet
then the servlet will be loaded
–
Similar advantages and disadvantages to Servlets, though easier construction of the HTML document
parts
Question
6. XML (10 marks)
Briefly describe the following protocols:
- XML
Answer (2 marks):
l
eXtensible
Markup Language: is used to describe metadata
l Users define their own set of tags
l An XML document does not “do” anything on its own
– Well-formed: follow XML syntax rules (single root tag, proper nesting of tags, etc.)
– Validity: conforms to restriction on the nature, order and number of tags in a well-formed XML document, specified in a separate document
- XML Schema
Answer (2 marks):
l
a formal definition of the syntax
of an XML language
l
expressed
in XML notation itself, provides support for namespaces, user-defined data
types, etc.
- XSLT
Answer (2 marks):
l
eXtensible
Stylesheet Language Templates
l allows the transformation of one XML document into another by specifying transformation rules
- SOAP
Answer (2 marks):
l SOAP [a.k.a. Simple Object Access Protocol, XML Protocol] - An XML packaging protocol, defines message formats and encoding rules
l
A transport neutral protocol for XML data interchange (but focusing on
HTTP)
l
Processing model (envelopes, intermediaries, ...)
l
SOAP Encoding
l
SOAP RPC
l
Protocol Bindings
l
Foundation of WS-*
- WSDL
Answer (2 marks):
l WSDL (Web Services Description Language) - An XML service description language
l
Standard for describing Web
services
–
Abstract interface for defining
operations and their messages
l
Messages contain either
document-oriented or procedure-oriented information
l
Bindings to message formats and
protocols
–
Defines how to locate the endpoint for
the service
l
Example: URLs for HTTP
–
Extensible (SOAP and HTTP extensions are
defined)
–
Written in XML, leverages XML schema
Question
7. P2P Systems (10 marks)
1. Describe how P2P systems differ from Client-Server Architectures.
Answer (3 marks):
l Computing paradigm where all the nodes have equivalent responsibilities and roles
l “neither introduces nor prohibits centralization”
l “sharing of resources through direct communication between consumers and providers”
l “a network architecture where all the available resources are located at the network edges”
l “the opposite of client-server”
2. What are (potential) advantages of the P2P approach?
Answer (2 marks):
l
Efficient use of resources
l
Scalability
l
Reliability
l
Ease of administration
3. Briefly describe and evaluate Napster, Gnutella, and KaZaA.
Answer (3 marks):
l Napster
ü
Centralised model
ü
Napster server ensures correct results
ü
Only used for finding the location of the files
Ø
Scalability bottleneck
Ø
Single point of failure
Ø
Denial of Service attacks possible
Ø
Lawsuits
l Gnutella
ü
Decentralised model
ü
No single point of failure
ü
Less susceptible to denial of service
Ø
SCALABILITY (flooding)
Ø
Cannot ensure correct results
l KaZaA
l
Hybrid of Napster and Gnutella
l
Super-peers act as local search hubs
–
Each super-peer is like a constrained Napster server
–
Automatically chosen based on capacity and availability
l
Lists of files are uploaded to a super-peer
l
Super-peers periodically exchange file lists
l
Queries are sent to super-peers
4.
How do Napster, Gnutella, etc. differ
from P2P systems such as CHORDS or CAN?
Answer (2 marks):
In Napster et al., data is placed
on peers as determined by user, prime challenge is to locate which peer holds
the data/file we are interested in. In CHORDS and CAN, the “system” places the
data on peers based on a distributed hash table model. The “system” then allows
efficient retrieval of that data while bounding the amount of information each
peer needs to maintain about other peers.